In our long experience of helping editorial and production staff transition to using eXtyles, we’ve observed that making the mental leap from formatting Word content to applying semantic structure to Word content is often one of the most challenging aspects of adopting an XML-driven workflow.
What are some differences between formatting and semantically structuring documents? Why is this challenging transition so important to make? What are some benefits of a semantic mindset? In this 3-part series of posts, we’ll discuss
- Why creating semantic structure in your content is useful and important
- How eXtyles uses Word paragraph styles, which may differ in minor or major ways from how they’ve traditionally been used in your workflow
- Some common challenges and pain points in the transition process
Are you sitting comfortably? Then let’s begin!
What we mean by semantic structure
At the most basic level, when we talk about semantic structure we are talking about identifying the elements of your content in terms of what they are, rather than in terms of what they look like. Identifying elements such as title, author/s, abstract, keywords, various levels of headings, block quotations, and references (and their elements!) makes it possible for both people and machines to answer questions like this:
- Who authored this document?
- What is the hierarchy of the document? What are its sections and subsections?
- What is this document about? What subjects does it cover?
- What sources does this document cite?
- Does this document contain tables, figures, maps, appendices, illustrations, equations?
To illustrate this idea of what things are versus what things look like, here are 2 versions of the same dummy text in Word:
 |
 |
Version 1 (left) uses some fairly typical visual formatting conventions—bold for a level 1 or A head, italic for a level 2 or B head, a block quote indented using a tab—to indicate some basic structure. In the Word Styles pane on the left-hand side of the screenshot, you can see that all paragraphs and headings are identified as “Normal”—that is, everything is on the same level. There’s no underlying hierarchy or other semantic structure in this document.
Version 2 (right) has some very basic structure built in, using just the built-in structural elements available in Word: specific paragraph styles for level 1 and 2 headings and for block quotes, and Normal style for regular text. The Styles pane reflects that basic structure, with Heading 1, Heading 2, and Quote.
Human reading vs automated processing
Why does this matter? The answer lies in the differences between human-readable data and machine-readable data—that is, content that is structured to allow automated processing.
For a human reader—one who is familiar with a certain set of text formatting conventions—the “structure” of Version 1 above is likely to be easy to interpret. Humans can also look at the content of an element for clues to its role in the document. In our very on-the-nose example, the text of each element is a literal description of its role (e.g., the text styled as Heading 1 reads “This is an A Head”), but in a real-world situation it might read “Introduction” or “Methods”. We’ve learned to interpret bold text as “stronger” than italics, so we easily identify the italic heading as subordinate to the bold heading, and the roman text blocks as subordinate to both. We’ve also learned the convention of the indented block quote, which allows us to interpret that indented paragraph as a different kind of text from the paragraphs above and below it.
For a machine, however, there’s no structure to be read or interpreted in Version 1, just an undifferentiated mass of data.
Version 2, on the other hand, while still completely human-readable, also contains at least the bare bones of a structure that allows automated processing.
As you can see, we haven’t lost any human readability in the switch from face formatting to Word styles, but we’ve gained a lot in terms of machine readability!
Why structured content matters
What do we mean by automated processing, and why is structuring your content to allow automated processing important?
The shift toward structuring for machine readability and automated processing can have many drivers, including national and international accessibility requirements; upload requirements from vendors and aggregators; and deposit requirements for archives, Crossref, and citation indexes—all of which have a major impact on publishers, authors, and readers. (Structured content can also be leveraged for more efficient workflows—for instance, using XML as the single source for creating PDFs, HTML, and EPUB.)
Here are a few examples of automated processing:
- Word’s Navigation pane, which shows you the structure of a styled document based on the “outline level” assigned to each style:
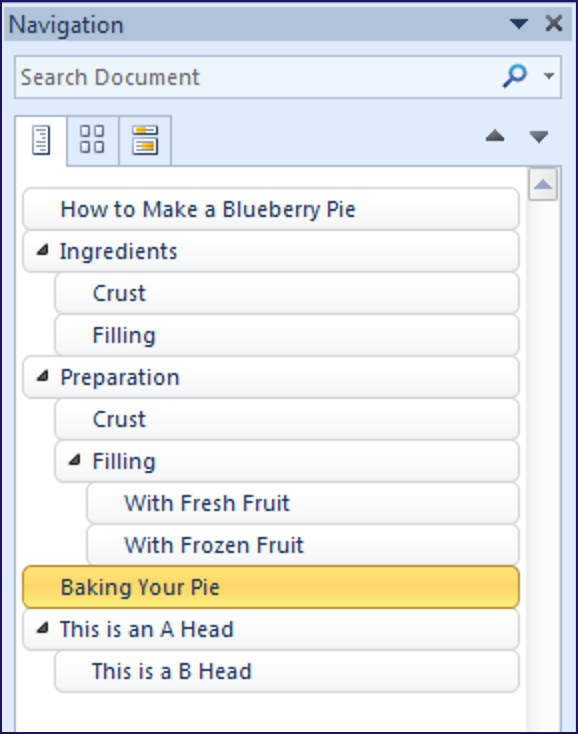
- the .css stylesheet associated with an HTML page or an EPUB file
- citation indexes that pull metadata from online publications
- an XSLT designed to transform XML into HTML, or one type of XML into another type
- a screen reader or other accessibility tool used by someone with a print disability
- the search function on a journal database such as JSTOR, or on a preprint server such as arXiv
- a Schematron examining your content for missing elements (e.g., funding disclosure) or missing data within sections (e.g., author affiliations in front matter)
Some of these use cases will be more relevant to your concerns than others—but all of them depend on access to structured content.The need for structured content to facilitate various types of automated processing—including multi-format publishing, maximizing discoverability, and creating accessible content—is a primary driver when publishers decide to adopt an XML-based workflow.
Old habits vs new goals
Chances are, you’re already using Word styles in your publishing workflow to facilitate your composition processes.
But, as the goals of your publishing operations continue to evolve—from producing print publications, to producing print and online content optimized for the human eye, to producing machine-readable content—the solutions, processes, and habits developed to help you meet earlier goals may be unhelpful or even create obstacles to meeting these new goals.
This means that as you start to adopt an eXtyles workflow, you may have some unlearning to do. Never fear! In the remainder of this series, we’ll discuss how eXtyles uses paragraph styles in creating structured content (Part 2) and how to overcome some of the most common challenges and pain points in moving from a format to a structure mindset (Part 3).