![]() Q. What do we want?
Q. What do we want?
A. Richer, connected, reusable, open metadata for all research outputs!
Q. When do we want it?
A. Yesterday!
Metadata 2020 and you
In their own words,
Metadata 2020 is a collaboration that advocates richer, connected, and reusable, open metadata for all research outputs, which will advance scholarly pursuits
for the benefit of society.
You’ll find the rest of the who, what, why, and how of the Metadata 2020 collaboration on their website.
The Metadata 2020 collaboration works towards its goals through Community Groups that embrace every
type of stakeholder group in scholarly communications: data publishers and repositories, funders, librarians, publishers, researchers, services, platforms, and tools. To join a Community Group, contact [email protected]!
Metadata 2020 and us
At Inera, metadata is a big part of what we do. As we continue to develop our editorial and XML software solutions, improving how they handle various kinds of metadata—including DOI, ORCID, CRediT, and funder metadata—is always on our minds. So the Metadata 2020 goal of richer, better-connected, reusable metadata really speaks to us.
Our #1 rule for working with metadata: Enter it once and enter it right. We also have some do’s and don’ts:
Do:
- Validate metadata early and often.
- Strive for single-source metadata.
- Reoptimize your workflow for more accurate and complete metadata.
Don’t:
- Do manually what you can do automatically.
- Copy and paste.
- Burden researchers with administrative tasks.
These principles shape how our software collects, handles, and exports metadata: Because we care about metadata, we make sure our software solutions take
metadata seriously, too.
So what does that look like in practice?
Enter it once, enter it right
The eXtyles Document Information dialog is designed with this principle in mind: the metadata you enter in this dialog box, whether during document activation or as a later update, persists through subsequent iterations of the Word file and is exported unchanged as part of the XML. You only have to enter the metadata once, but you can also use Update Document Information to check that you’ve entered it right!
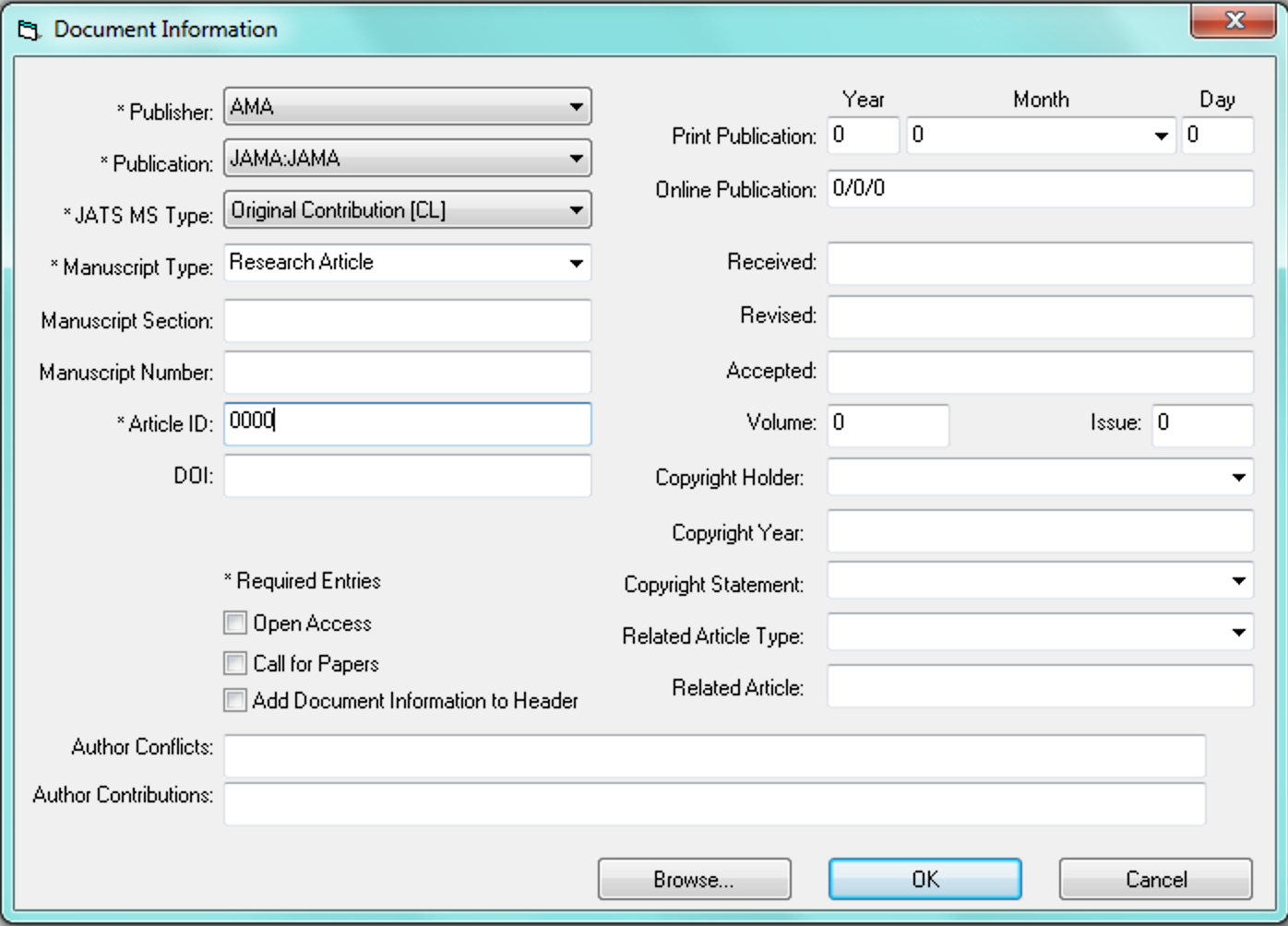
When we custom-configure your Document Information dialog, we ask some key questions: which metadata fields will be included? Of the included fields, which will be mandatory and which optional? Where and how will we restrict what can be entered in particular fields? (For example, customers will usually want their DOI prefix to be pre-filled in the DOI field; most will use a drop-down list of document types.) Why is this important? Because the more fields a user has to fill in manually, the more opportunities there are for error.
Don’t do manually what you can do automatically
The optional Metadata Browse feature takes “enter it once, enter it right” one step further for customers whose documents arrive via online submission systems, allowing users to populate the Document Information dialog fields by simply importing the metadata already entered by the author. Metadata Browse also embodies two other Inera metadata rules: Don’t do manually what you can do automatically, and don’t copy and paste.
Similarly, the PubMed and Crossref Linking and Correction components common to both eXtyles and Edifix eliminate manual searching, copying, and pasting of PMID and DOI links, so your end-matter metadata are as correct and complete as possible.
Don’t copy and paste
A common workflow for getting authors’ ORCID iDs from the submission system to the final XML file involves copying and pasting, which can lead to errors and, most importantly, breaks the chain of authentication. We designed the eXtyles ORCID Integration Suite to solve this problem; here’s how it works (video includes closed captioning):
Validate early and often
The eXtyles Document Information dialog includes default and configurable tools for keeping your metadata consistent, such as dropdown lists of document types, pre-filled DOI prefixes, and language codes. We can also configure eXtyles to prompt you when a document’s metadata may be getting stale (contact us to learn more about this optional feature).
A single metadata source
With eXtyles Metadata Extraction, we’ve fully automated the process of collecting metadata from author-submitted documents. This technology, which can be integrated into online submission systems, uses sophisticated automated analysis to accurately identify metadata elements in an author-submitted document and convert them to XML. That XML file then becomes the single source of metadata for the article, from submission through to publication.
Don’t burden researchers with administrative tasks
If there’s anything researchers enjoy even less than filling in dozens of metadata fields in a journal submission system, it’s being asked to supply metadata that’s already fully provided in their manuscript. When submission systems integrate eXtyles Metadata Extraction, authors can simply review and confirm metadata entries in the system fields, rather than having to enter them by hand—which not only reduces manual data-entry errors and blank metadata fields but also reduces frustration!
Metadata 2020, Inera, and you
Metadata 2020 is there to advocate for richer, connected, reusable, open metadata, and Inera is here to help you get all your metadata right!